
远程面对面交互对于工作、娱乐和人机关系都十分重要。尽管这种面对面的交互可以通过2D视频会议或虚拟现实实现,但远程呈现系统无法正确呈现眼神接触和社交注视信号的交流。有人曾提出通过在2D视频会议中重定向视线来实现眼神交流,但2D视频会议缺乏真实生活中的3D沉浸感。
为了解决所述问题,Facebook开发了一种虚拟现实面对面交互系统,并专注于再现逼真的注视信号和眼神交流。为了做到这一点,团队构建了一个可通过VR头显摄像头制作动画的三维虚拟化身模型,从而在虚拟现实中精确地追踪和再现人类的注视信号。

这项研究的主要贡献包括:一个可共同学习,并能够更好地表示注视方向和上面部表情的3D人脸和眼球模型;一种将左右眼注视从彼此和面部其他部分分离开来的方法,从而令模型能够代表前所未见的眼神和表情组合;以及一个用于支持头显摄像头构建精确动画的注视感知模型。定量实验表明,这一方法可以获得更高的重建质量,而定性结果显示所述方法可以大大改善VR虚拟化身的临场感。
VR虚拟化身都是对应真实的实时CG渲染。简单来说,Facebook的方法将眼球和人脸分离,并单独控制渲染,最后再整合配准,从而实现一系列逼真的眼神+表情组合。
1. 眼球模型的实时单独渲染
具体而言,研究人员将注视点作为解码器的条件变量,从而实现显式注视点控制。要做到这一点,首先通过包含多个摄像头的头显追踪用户眼睛,并从多视角训练图像中估计出注视点。
对于每一帧,团队利用检测器在多个不同的输入视图中沿着边缘检测关键点,然后沿着边缘将关键点重投影至多视角图像,并优化每一帧的眼球位置和方向以匹配关键点。这样就可以为每个序列拟合一个几何眼睛模型,包括每帧对每个眼睛方向的估计。对于几何眼睛模型,团队将其定义成由两个球体组合的曲面,围绕边界线性混合。
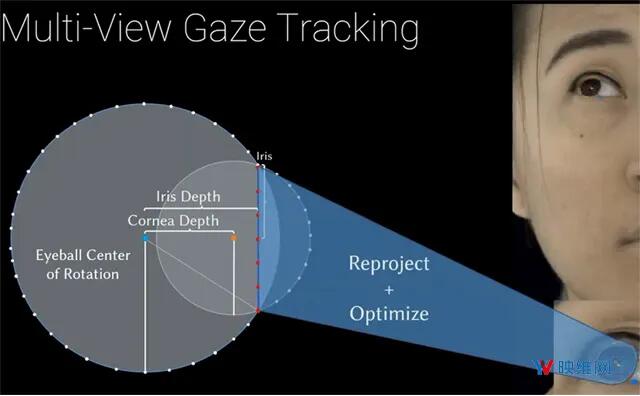
为了确保在所有的会聚距离正确控制模型的显式注视方向,模型必须允许对每只眼睛进行独立控制。所以,团队将控制面部地代码分解成控制左眼区域和右眼区域,并在训练过程中添加区域损失(Region Loss)以惩罚解码输出的差异。例如对左眼应用区域损失,当改动与左眼区域无关的代码时,左眼将不会运动。
由于模型同时产生几何和纹理,团队同时将类似的惩罚应用到纹理,这样当你改变控制左眼以外区域的代码时,左眼纹理同样不会改变。通过这样单独控制每只眼睛的注视,系统可以产生更为逼真的眼神交互。

通过上述方法产生的眼球模型可以为眼球几何提供一个粗略的初始估计,但如果要为虚拟化身渲染眼球,我们必须精进估计并生成纹理。给定一个多视角面部捕获,团队利用上述模型的初始形状参数估计每个帧的眼球方向。然后,团队移除覆盖眼睛的几何,并替换以新的眼球几何。对于渲染新的眼球几何,团队利用了视点,眼球方向和眼脸形状,以及一系列的眼球纹理解码器和扭曲算法。
团队将这个模型称为显式眼球模型(EEM),从而强调眼球是一个独立的、直接控制的几何组件。
相关论文:
The Eyes Have It: An Integrated Eye and Face Model for Photorealistic Facial Animation
https://paper.nweon.com/2968
2. 前所未见的眼神和表情组合
研究人员指出,这可以实现前所未见的眼神和表情组合。这是如何实时结合并驱动的呢?
由于这是一个包含眼球模型和人脸模型的联合模型,团队同时解码了面部几何和纹理,移除覆盖原来的眼球几何,添加上述新的眼球几何,旋转眼球几何以匹配注视点输入,并将其放到面部。接下来团队为眼球解码纹理,并渲染完整的网格几何渲染,优化模型参数以匹配捕获图像,通过虚拟化身配准系统(Avatar Correspondence System)实现虚拟化身渲染和捕获图像的配准。

在训练期间,团队时使用包含九个摄像头的头显来更好地捕获面部。然后配准模型(coreespondence model)估计表情,相对于面部的头显姿态和注视方向,并将其作为输入来为每个camera视点解码网格和纹理。团队接下来通过浅层神经网络(shallow network)将虚拟化身纹理转换至头显域,渲染虚拟化身,并端到端地优化整个系统,使用差分渲染来匹配头显图像。

对于仅搭载三个摄像头的头显,团队构建一个共享的特征映射来描述面部,然后回归到表情代码,以及针对每个眼睛的bounding box。利用位于bounding box的特征,团队可以预测注视点,并产生独立于表情的注视点,然后利用所述输入来实时驱动虚拟化身。
—
(文章转载自:映维网;原文链接:https://yivian.com/news/76177.html)