
6DoF 是指用户可以在物理空间内任何位置、任何方向自由地观看节目素材。用户移动可以被传感器或输入控制器捕获到,同时支持用户空间位移和头部姿态变化。典型的应用场景是用户自由走动并同时通过 HMD 观看 VR 视频内容。
6DoF VR视频拍摄制作方法
(1 1)摄像机拍摄
6DoF 中,用户可以在场景中移动。在拍摄 6DoF 的 VR 视频时,必须通过“真实”摄像机在整个视区中记录足够的视图,以允许最终在用户的渲染设备中进行高质量的视图合成。在实际拍摄中,相机的数量、位置、角度等取决于所需内容的质量,而质量又取决于许多因素,例如:视区的大小、与相关物体的距离、物体的类型、用户的预期运动等。如果有一些物体离用户很近,则相对较小的用户动作将显著改变物体的视线(即大视差),并且会迅速遮挡物体的某些部分,相反,如果物体离得较远则看不见。为了捕获此信息,与拍摄远处的物体相比,将需要更多的摄像机。因此,
6DoF 摄像机有多种设置。
相机往往基于固定的角度间隔摆放,角度间隔越小,视角切换的平滑度会越高,但同时相机的数量和系统成本也会随之增加,所以如何利用尽可能少的相机拍摄出平滑度高的 6DoF VR 视频是前端采集的关键任务。除此之外,采集系统的同步性和标定精度也是影响拍摄质量的两个主要指标,为了拍摄出接近静止的多角度精彩瞬间,要求相机支持毫秒级别的同步触发拍摄。直播图像要围绕一个焦点旋转,支持焦点的数量和可选范围的大小也是衡量一个拍摄系统的关键所在。
较小的摄影机装备,可在较小的观看区域内捕捉 6DoF VR:

具有许多摄像头的 6DoF VR 设置的 Intel Studio:

(2 2)CG 仿真制作
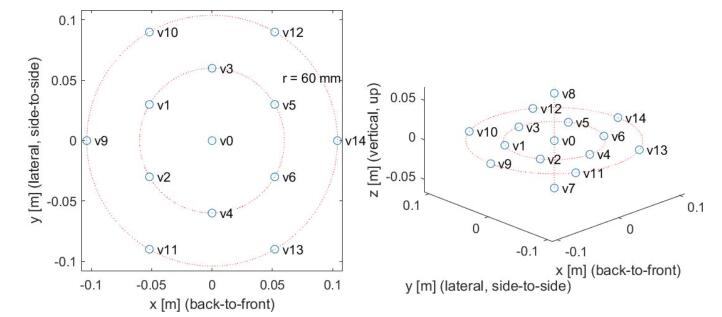
6DoF 内容也可以由 CG 仿真制作,可以从 CG 模型中渲染出所需的“真实”视图,而无需物理摄像机。例如,对于图 17 中的场景,图 18 显示了 CG 所生成的虚拟摄像机视图集。从这 15 个视图集合中,实际上可以在视图合成中生成任何其他视图。
VR 视频全景视图和相应的深度图:

15 个虚拟 VR 全景摄像机的位置:
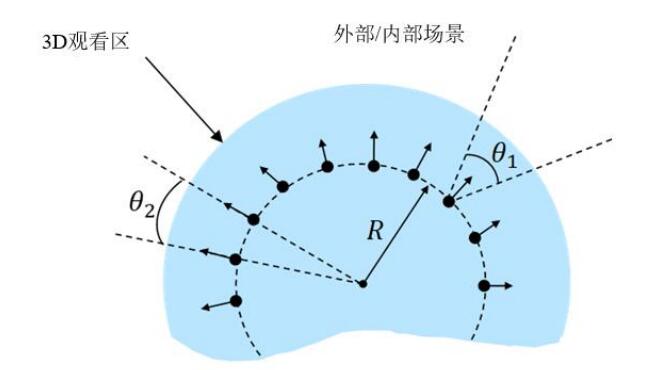
通常,在拍摄 6DoF VR 场景时,有两种方法:由外而内和由内而外。下图展示了由外而内拍摄时的摄像机布置,可捕捉球场上的动作。这种方式也适用于用户与正在进行的事件相对较远的其他场景。
由外而内 VR 拍摄体育比赛(点代表摄像机,箭头代表镜头对称轴的方向):

对于用户想沉浸在动作中间的用例,例如,身临其境的旅行或一级方程式赛车的驾驶舱,由内而外的拍摄更为合适。图 20 所示为这种情况下典型的摄像机布置。
由内而外的 VR 拍摄的典型摄像机布置:
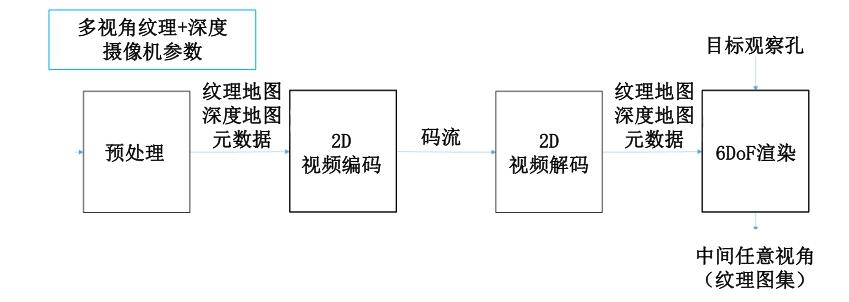
编解码
典型的编码问题是发送方采用预定义类型的输入,将其编码为码流并发送。接收器了解编码方案,可使用该方案对接收到的码流进行解码,从而重建输入视频。广播应用的视频压缩是有损编码,这意味着无法完全重建输入视频。在某种程度上,6DoF VR 视频也会发生同样的情况,但情况要复杂一些。6DoF 编解码器的系统框图:
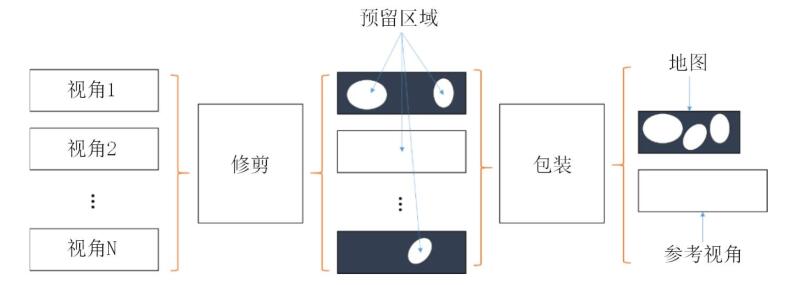
(1 )6DoF 编码
6DoF 编码器由可转换输入数据的预处理器组成。预处理器的第一步是搜索冗余像素并裁剪它们。例如,平坦的白墙的外观在很大程度上不依赖于视点,因此,如果从一个视图中看到它可能就足够了。对于树木或镜面物体等复杂对象,应保留多个视点。第二步是将保留的区域打包到一帧图像中。将图像小块打包成帧图像在计算机图形学中称为纹理图集。此外,对于 6DoF 还存在相应的深度图集。图集元数据对图集中的图像小块与裁剪后的源视图之间的关系进行编码,该元数据对于重建至关重要。预处理器流程图如图所示:
经过预处理器之后的数据通过一个或多个二维视频编码器(例如 H.265、AVS2)进行传输。
6DoF 编码器可接收场景的多视图表示,包括:每个视图(摄像机)的纹理(颜色)框、每个视图的深度图、描述摄像机的摄像机参数(内部,例如焦距)和摄像机的空间布局(外部,即相对位置和方向)。
6DoF 编码器将上述多视图表示作为视图空间的采样,并传输一个支持视图插值的视图空间表示。
(2 )6DoF 解码
6DoF 解码器能够在保真度损失情况下重建上述所有信息。另外,6DoF 解码器还可以重建中间视点。因此,6DoF 解码器包括二维视频解码器和渲染器。
终端渲染显示
6DoF 视频的典型渲染模型具有以下步骤:
(1)实时解码一个或多个基本视频流,例如,一个纹理图集和一个深度图集。
通常,解码将直接进入 GPU 可访问的内存。
(2)实时解码元数据,包括源视图参数以及如何将其打包到视频流中(即图集
中的图像小块)。
(3)呈现帧图像时,接收对视口位置和方向(姿势)的预测。
(4)将元数据和目标视口姿势转换为 GPU 渲染指令,以并行合成块或面片,例
如:重新投影像素以创建带纹理的网格、栅格网格。
(5)混合在目标视口中重叠的面片。
(6)修补所有丢失的像素。
(7)呈现视口。
(文章内容摘自:5G 高新视频 — VR 视频技术白皮书( 2020))